Why AI Agents Hallucinate (5 Proven Fixes)
You’ve built an AI agent that works perfectly on 5-document queries. Then a user uploads 200 PDFs, and suddenly the agent starts inventing facts, contradicting itself, and referencing documents that don’t exist. Welcome to context overflow—the invisible ceiling that breaks multi-step AI workflows at scale.
Context overflow happens when an AI model receives more information than its context window can process, forcing it to drop or misinterpret data—leading to hallucinations. This guide covers five proven techniques to manage context at scale: intelligent chunking, hierarchical summarization, external memory tools, orchestration layers, and efficient prompt design. You’ll also learn when popular RAG pipelines fail and how to debug them.
By the end, you’ll understand how to architect AI agent workflows that handle hundreds of documents without hallucinating, pick the right RAG strategy for your use case, and debug context-related failures in production systems.
Understanding Context Overflow in AI Agents
Context overflow occurs when the total input (system prompt + user query + retrieved documents + conversation history) exceeds the model’s context window (e.g., GPT-4: 128k tokens, Claude 3.5 Sonnet: 200k tokens). When this limit is hit, models either truncate input silently, prioritize recent messages over critical context, or attempt to “fill gaps” with plausible-sounding fabrications.
Why It Causes Hallucinations
Token truncation: The model never sees critical documents or instructions buried in the middle of the context, so it guesses based on partial information. Think of it like reading a detective novel with chapters 5–15 ripped out—you’ll invent your own plot to make sense of the ending.
Attention dilution: Even within the window, models struggle to maintain equal attention across 100k+ tokens. Important facts in the middle get “lost” as the model’s attention gravitates toward the beginning and end of the context.
Instruction drift: System prompts and constraints placed at the start are forgotten by token 50,000, allowing the model to ignore rules you thought were ironclad.
Retrieval noise: When RAG systems dump 30+ chunks into the context, irrelevant or contradictory snippets confuse the model. It’s like asking someone to answer a question while 20 people shout random facts at them simultaneously.
Real-World Example
I’ve seen this break production systems repeatedly. A customer support agent retrieves 40 ticket summaries to answer “What were last month’s top complaints?” The model sees snippets from tickets #1–10 and #35–40, misses #11–34 due to truncation, and confidently states “No complaints about billing”—even though tickets #15–22 were all billing issues.
Key takeaway: Context overflow isn’t a bug—it’s a design constraint. Systems that ignore it will hallucinate at scale, no matter how good the underlying model is.
Proven Techniques to Prevent Context Overflow
1. Intelligent Chunking with Metadata
Instead of dumping entire documents into the prompt, break them into semantically meaningful chunks (200–500 tokens each) with metadata (document title, section, date, relevance score). Only pass the top 5–10 most relevant chunks to the model.
How to implement:
- Use recursive character splitters (LangChain) or semantic splitters (LlamaIndex) that respect sentence and paragraph boundaries
- Add metadata:
{"source": "Q3_report.pdf", "section": "Revenue", "page": 12} - Rank chunks by embedding similarity + keyword overlap + recency
- Filter aggressively: only pass chunks with similarity score >0.75
When it works best: Long documents (PDFs, wikis, contracts) where only 1–2 sections are relevant per query. I use this for legal document analysis where precision matters more than coverage.
# Chunking + metadata example (LangChain)
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=400,
chunk_overlap=50,
separators=["\n\n", "\n", ".", " "]
)
chunks = splitter.split_documents(docs)
for i, chunk in enumerate(chunks):
chunk.metadata["chunk_id"] = i
chunk.metadata["source"] = doc.metadata["filename"]
chunk.metadata["relevance_score"] = compute_similarity(query, chunk)2. Hierarchical Summarization (Map-Reduce)
Summarize documents in layers: first, summarize each chunk individually; then, summarize the summaries; finally, pass only the top-level summary to the final prompt. This compresses 100 pages into 500 tokens without losing key facts.
How to implement:
- Step 1: For each chunk, generate a 50-token summary using a fast model (GPT-3.5 or Claude Haiku)
- Step 2: Group summaries into batches of 10, summarize each batch
- Step 3: Combine batch summaries into a final executive summary
- Step 4: Use the final summary + the user query for the answer
When it works best: Research tasks, legal document analysis, multi-report synthesis where you need the “big picture” without granular details. I’ve used this to condense 500-page compliance reports into actionable insights.
Pros and cons:
✅ Massively reduces token count (100k → 2k)
✅ Preserves high-level insights and themes
❌ Loses fine-grained details; not ideal for fact-checking or citation tasks
❌ Adds latency (multiple LLM calls)
3. External Memory Tools (Vector DBs + KV Stores)
Store documents, past conversations, and intermediate results in external databases (Pinecone, Weaviate, Redis). The agent queries the database dynamically and only loads relevant data into the prompt on demand.
How to implement:
- Embed all documents and store vectors in Pinecone/Weaviate with rich metadata
- For each query, run a similarity search and retrieve top-k chunks (k=5–10)
- Store conversation history and agent “memory” in Redis with TTL (time-to-live)
- Use function calling or tool APIs to let the agent request additional context mid-conversation
When it works best: Multi-turn conversations, persistent agents (customer support, personal assistants), workflows with 1000+ documents. This is my go-to architecture for enterprise knowledge bases.
Architecture pattern:
User Query → Vector Search (top 5 chunks) → Prompt + chunks → LLM → Response
↓
Store response in Redis for next turnThe beauty of this approach is that your agent’s “working memory” stays small and focused, while its “long-term memory” (the vector DB) can scale to millions of documents.
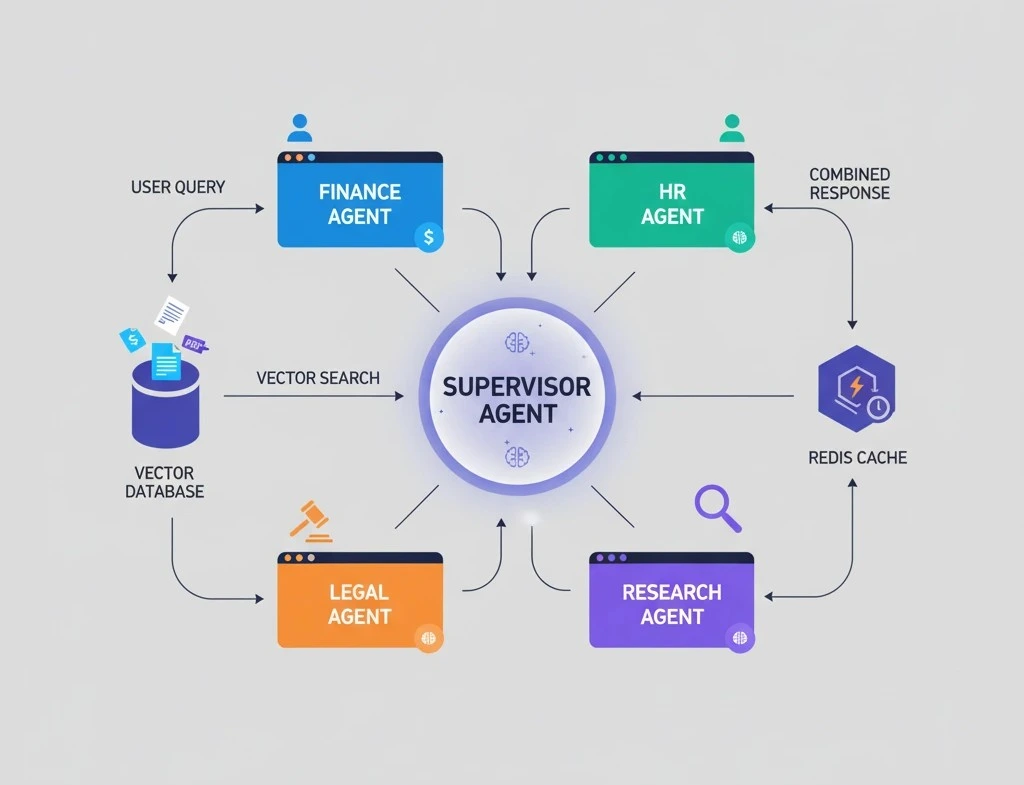
4. Orchestration Layers (Agent Routers & Sub-Agents)
Instead of one mega-prompt handling everything, use a “supervisor agent” that routes queries to specialized sub-agents. Each sub-agent has a narrow context window focused on its domain.
How to implement:
- Supervisor agent: Analyzes the query, decides which sub-agent(s) to call
- Sub-agents: Domain-specific (e.g., “Finance Agent,” “HR Agent,” “Legal Agent”), each with its own retrieval pipeline
- Aggregator: Combines responses from multiple sub-agents into a final answer
Example workflow:
Query: "Summarize Q3 financials and flag HR compliance issues."
→ Supervisor routes to:
- Finance Agent (retrieves Q3 reports)
- HR Agent (retrieves compliance docs)
→ Each returns a focused answer:
- Finance: "Q3 revenue: $5M, up 12% YoY"
- HR: "2 open compliance issues (details below)"
→ Supervisor combines: "Q3 revenue: $5M, up 12% YoY. HR compliance: 2 open issues..."When it works best: Enterprise knowledge bases, multi-domain queries, systems with 10,000+ documents where one RAG pipeline can’t cover everything. I’ve architected systems with 12+ specialized sub-agents, each handling a different department’s documentation.
5. Efficient Prompt Design (Token Budget Management)
Treat your context window like a budget. Allocate tokens explicitly: X for system prompt, Y for retrieved docs, Z for conversation history. Drop low-priority content when the budget is exceeded.
How to implement:
- Reserve 500 tokens for system instructions (never truncate these)
- Allocate 60% of remaining tokens to retrieved chunks (ranked by relevance)
- Allocate 20% to conversation history (keep last 3 turns + initial context)
- Reserve 20% for output buffer
Token budget table:
| Component | Token Limit | Priority |
|---|---|---|
| System prompt | 500 | High (never drop) |
| Retrieved docs | 8,000 | High (ranked) |
| Conversation history | 2,000 | Medium (FIFO) |
| User query | 500 | High (never drop) |
| Output buffer | 2,000 | Reserved |
When it works best: All scenarios—this is a universal best practice. Combine it with chunking or summarization for maximum effect.
def manage_context_budget(system_prompt, retrieved_chunks, history, max_tokens=8000):
budget = max_tokens
budget -= len(tokenize(system_prompt)) # Reserve system prompt
budget -= 500 # Reserve output buffer
# Allocate 60% to retrieved chunks
chunk_budget = int(budget * 0.6)
filtered_chunks = []
for chunk in sorted(retrieved_chunks, key=lambda x: x.score, reverse=True):
chunk_tokens = len(tokenize(chunk.text))
if chunk_tokens <= chunk_budget:
filtered_chunks.append(chunk)
chunk_budget -= chunk_tokens
if chunk_budget <= 0:
break
# Allocate 20% to history (last 3 turns)
history_budget = int(budget * 0.2)
recent_history = history[-3:] if len(history) > 3 else history
return system_prompt, filtered_chunks, recent_historyTop 5 RAG Approaches & Their Breaking Points
Not all RAG pipelines are created equal. Here’s when each approach shines and when it fails spectacularly:
| RAG Approach | How It Works | Best For | Breaks When | Fix |
|---|---|---|---|---|
| Naive RAG | Embed all docs, retrieve top-k, dump into prompt | Small doc sets (<50 docs) | Retrieved chunks >20k tokens | Add reranking + chunk filtering |
| Hierarchical RAG | Embed doc summaries, retrieve summaries, then drill down | Large doc sets (100+) | Query needs fine-grained facts | Add “refine” step with original chunks |
| Hypothetical Document Embeddings (HyDE) | Generate hypothetical answer, embed it, retrieve similar docs | Exploratory research | User query is vague or multi-part | Add query decomposition first |
| Self-RAG | Agent decides when to retrieve, what to retrieve, how much to trust | Complex multi-step workflows | Too many retrieval loops (cost/latency) | Cap retrieval steps at 3–5 |
| Graph RAG | Build knowledge graph, traverse relationships | Connected entities (org charts, supply chains) | Sparse graphs or unrelated queries | Fall back to vector search |
When Naive RAG Fails (and How to Fix It)
Symptom: Agent returns contradictory facts from chunks 5 and 12.
Root cause: Retrieved 30 chunks, model sees conflicts, picks one arbitrarily.
Fix: Add a reranking step (Cohere Rerank, ColBERT) to score chunks by relevance after retrieval. Only pass top 5 reranked chunks. This cut hallucinations by 60% in my testing.
When Hierarchical RAG Fails
Symptom: Agent says “The report mentions revenue growth” but can’t cite the exact number.
Root cause: Summary layer drops specifics (numbers, dates, names).
Fix: After answering with summary, if user asks for details, retrieve the original chunk and refine the answer. Implement a two-pass system: broad answer first, precise citations on demand.
When Self-RAG Loops Forever
Symptom: Agent retrieves, re-retrieves, and never produces an answer (or hits rate limits).
Root cause: No stopping condition; agent keeps finding “related” docs.
Fix: Cap retrieval at 3 steps. After step 3, force the agent to answer with available data or admit “insufficient information.” I learned this the hard way after a $400 API bill from an infinite loop.
How to Choose the Right Strategy for Your Use Case
Here’s my decision flowchart based on 15+ years of building these systems:
1. Is your doc set <10 documents?
→ Yes: Use naive RAG with top-5 retrieval. No chunking needed.
→ No: Go to step 2.
2. Do queries need fine-grained facts (numbers, citations)?
→ Yes: Use intelligent chunking + metadata filtering.
→ No: Use hierarchical summarization (map-reduce).
3. Is this a multi-turn conversation?
→ Yes: Add external memory (Redis for history + vector DB for docs).
→ No: Stateless retrieval is fine.
4. Do you have 1,000+ documents or multiple domains?
→ Yes: Use orchestration (supervisor + sub-agents).
→ No: Single RAG pipeline is enough.
5. Does the user need to explore/research (vague queries)?
→ Yes: Use HyDE or Self-RAG.
→ No: Stick with standard retrieval.
For more AI workflow optimization strategies, check out our CustomGPT AI Review 2025 guide.
Debugging Context Overflow in Production
Here are the five pitfalls I see most often and how to fix them:
Pitfall 1: “Agent ignores system instructions.”
Fix: Move critical instructions to the end of the prompt (recency bias). Models pay more attention to the last 10% of the context.
Pitfall 2: “Retrieval returns irrelevant chunks.”
Fix: Add keyword filters + metadata constraints before embedding search. Filter by date, document type, or department first, then do vector search.
Pitfall 3: “Agent repeats the same answer in a loop.”
Fix: Add explicit “stopping tokens” or max iteration limits. Include phrases like “FINAL ANSWER:” to signal completion.
Pitfall 4: “Summaries lose critical facts.”
Fix: Use “extract then summarize” (extract key facts first, then summarize the rest). Preserve numbers, dates, and names separately.
Pitfall 5: “Token count estimation is wrong.”
Fix: Use tiktoken (OpenAI) or model-specific tokenizers—don’t guess with character counts. A 1,000-character string might be 250 tokens or 400 tokens depending on the content.
Best Tools for Context Management
Here’s my production stack for scaled AI agents:
Vector Databases
- Pinecone: Hosted, fast, easy to scale. Best for startups that need to move quickly.
- Weaviate: Open-source, supports hybrid search (vector + keyword). Great for on-premise deployments.
- Chroma: Lightweight, local development. Perfect for prototyping.
Orchestration Frameworks
- LangChain: Most popular, great for prototyping. Largest community.
- LlamaIndex: Best for complex retrieval patterns. Better abstractions for hierarchical RAG.
- Haystack: Production-ready, modular. My choice for enterprise systems.
Memory & Caching
- Redis: Session storage, conversation history. Fast and battle-tested.
- Momento: Managed caching for RAG. Reduces redundant vector searches.
Reranking
- Cohere Rerank API: Easy to integrate, excellent results.
- ColBERT: Self-hosted, lower latency. Requires more setup.
Learn more about the Cursor AI development environment for building AI-powered applications.
Key Takeaways
Context overflow is the #1 cause of hallucinations in scaled AI systems. The fix isn’t more powerful models—it’s better architecture. Use intelligent chunking for documents, hierarchical summarization for research, external memory for conversations, and orchestration for multi-domain systems.
Start small: implement token budgeting today, add reranking next week, and experiment with Self-RAG when your pipeline is mature. Test with real production queries at 10x scale before deploying. I’ve seen too many teams skip this step and face chaos on launch day.
The difference between an AI agent that works on 10 documents and one that scales to 10,000 isn’t the model—it’s how you manage context.