Helicone Review: The Open-Source AI Gateway

If you’re building anything with AI in 2025, you’ve probably felt the pain: swapping between OpenAI, Anthropic, Mistral, and a dozen other providers, trying to debug why your prompts are burning through tokens, and wondering if there’s a better way to monitor what’s actually happening behind the scenes.
I’ve been there. After spending the last year testing AI tools and building automations, I can tell you that managing multiple LLM providers is chaos without the right infrastructure. That’s exactly why Helicone caught my attention—and after diving deep into this open-source API gateway, I’m convinced it’s one of those rare tools that solves a real problem elegantly.
Let me walk you through what Helicone actually does, how it compares to the alternatives, and whether it deserves a spot in your AI development stack.
What Exactly Is Helicone?
Helicone is an open-source AI API gateway that sits between your application and whatever LLM providers you’re using. Think of it as a unified control center for all your AI API calls—whether you’re hitting OpenAI’s GPT-4, Anthropic’s Claude, Google’s Gemini, or any of the 100+ models it supports.
But it’s more than just a passthrough. Helicone gives you:
The Core Value Proposition:
- One SDK for 100+ models: Write your code once, switch providers with a single line change
- Complete observability: See every request, token, error, and cost in real-time
- Smart routing and failover: Automatically balance traffic and handle provider outages
- Zero markup pricing: Pay only what the providers charge—no hidden fees
- Developer-first approach: Built by engineers who actually use LLMs in production
Here’s what sets Helicone apart from building your own logging system or using provider-specific dashboards:
| Feature | What You Get |
|---|---|
| Open-Source Gateway | Fully inspectable codebase, community-driven development, no vendor lock-in |
| 100+ Models Supported | OpenAI, Anthropic, Mistral, Cohere, Google Gemini, Groq, AWS Bedrock, Azure OpenAI, and more |
| LLM Routing | Intelligent traffic management, failover, load balancing across providers |
| Monitoring & Debug | Full request tracing, token-level visibility, error diagnostics |
| Usage Analytics | Track requests, tokens, costs, and latency across users, projects, and keys |
| Zero Markup | Transparent pricing—only pay Helicone’s flat fee plus provider costs at 1:1 rates |
| Free Forever Plan | 10,000 requests/month free, perfect for side projects and testing |
Getting Started: The Easiest Integration I’ve Seen
One of Helicone’s biggest selling points is how ridiculously simple it is to integrate. I’m talking genuinely minimal friction—something that’s rare in the observability space.
The Onboarding Experience
- Sign up at helicone.ai (no credit card required for the free tier)
- Get your Helicone API key from the dashboard
- Add one line of code to your existing setup
- Watch requests flow into your real-time dashboard
That’s it. Seriously.
Here’s what the actual code looks like for OpenAI integration:
from openai import OpenAI
client = OpenAI(
api_key="your-openai-key",
base_url="https://oai.helicone.ai/v1", # This one line routes through Helicone
default_headers={
"Helicone-Auth": "Bearer your-helicone-key"
}
)
response = client.chat.completions.create(
model="gpt-4",
messages=[{"role": "user", "content": "Hello!"}]
)Notice what you’re not doing: completely rewriting your API calls, migrating data, or learning a complex new framework. You’re literally just changing the base URL and adding a header. Your existing code continues to work exactly as before, but now every request flows through Helicone’s gateway where it gets logged, analyzed, and routed.
Language and Framework Support
Helicone supports virtually every language and framework you’d actually use for LLM development:
- Python (OpenAI SDK, LangChain, LlamaIndex)
- JavaScript/TypeScript (Node.js, Vercel AI SDK)
- REST API (works with curl, HTTP clients in any language)
- Streaming support for real-time responses
The team behind Helicone clearly understands developers. There’s even a quote on their homepage: “The most impactful one-line change I’ve seen applied to our codebase.” After testing it myself, I get why someone would say that.
Core Features: What Makes Helicone Worth Using
Let me break down the features that actually matter, based on my hands-on experience and the real-world scenarios where Helicone shines.
One SDK, 100+ Models: Provider Flexibility at Its Best

This is the headline feature, and it delivers. Helicone supports over 100 LLM models from major providers:
- OpenAI: GPT-4, GPT-4 Turbo, GPT-3.5, o1, o1-mini
- Anthropic: Claude 4.5 Sonnet, Claude 4 Opus, Claude 3.5 Haiku
- Google: Gemini 1.5 Pro, Gemini 2.0 Flash
- Open-source: Mistral, Llama via Together.ai, Groq
- Enterprise: AWS Bedrock, Azure OpenAI
Why does this matter? Because vendor lock-in is real, and AI provider landscapes shift fast. Maybe OpenAI raises prices. Maybe Anthropic’s Claude suddenly becomes better for your use case. Maybe you want to A/B test different models for cost vs. quality.
With Helicone, switching providers is literally changing one word in your code:
# From this:
model="gpt-4"
# To this:
model="claude-sonnet-4-5-20250514"Everything else—logging, analytics, error handling—continues working because it’s all managed by Helicone’s gateway layer. This is genuinely powerful for teams that need to stay agile. If you’re curious about how newer models like GPT-5.1 are changing the landscape, Helicone makes it trivial to test them.
Smart LLM Routing and Failover
Here’s where Helicone moves from “nice dashboard” to “production infrastructure.” The routing features let you:
- Load balance across multiple providers or models
- Automatic failover if one provider is down or slow
- Cost optimization by routing cheaper models for simple tasks
- A/B testing different models with traffic splitting
Example scenario: You’re running a customer support bot. Most queries are simple and can use GPT-3.5, but complex technical questions need GPT-4. Helicone can route based on rules you define, saving you money without sacrificing quality.
Or imagine OpenAI has an outage (it happens). With failover configured, your requests automatically reroute to Claude or another backup provider. Your users never see an error—they just get a response, maybe 200ms slower.
This kind of reliability used to require building your own orchestration layer. Now it’s built into the gateway.
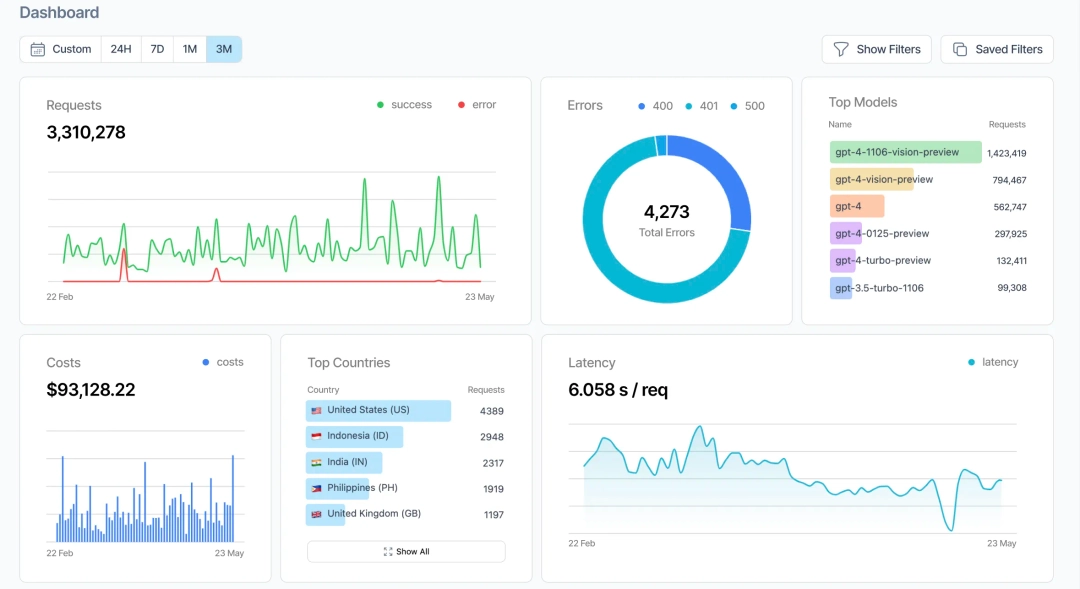
Debug, Trace, and Monitor: Visibility That Actually Helps
If you’ve ever tried to debug why your LLM app is behaving weirdly, you know the frustration. Was it the prompt? The temperature setting? A random token that threw off the response? Without proper logging, you’re flying blind.
Helicone’s dashboard gives you:
- Real-time request logs: Every API call, with full request and response bodies
- Token-level visibility: See exactly how many tokens each request consumed
- Error tracking: Failed requests with detailed error messages and stack traces
- Latency metrics: How long each request took, broken down by provider
- Cost tracking: Real-time spend monitoring per request, user, or project
The interface is clean and functional—no unnecessary complexity. You can filter by user, model, date range, or error status. Click into any request to see the full details: the exact prompt sent, the response received, metadata like temperature and max tokens, and the final cost.
This is invaluable for debugging. I’ve saved hours by being able to quickly identify which prompts are burning tokens or causing errors, without having to instrument custom logging into my codebase.
Analytics and Observability: Know What’s Actually Happening
Beyond individual request debugging, Helicone provides aggregate analytics that help you understand patterns:
- Request volume trends: Are you scaling up or seeing traffic spikes?
- Cost analysis: Which models or features are eating your budget?
- User-level tracking: Who’s making the most requests? (Great for usage-based billing)
- Performance benchmarks: Compare latency and success rates across providers
- Custom dashboards: Query and visualize your data however you need
The analytics aren’t just vanity metrics—they’re actionable. I can see that 80% of my costs come from 20% of users, or that switching from GPT-4 to Claude Sonnet for certain tasks could save 40% on token costs without quality loss.
For teams building AI products, this observability is crucial for optimization and cost management. Helicone essentially gives you the analytics suite that would take months to build in-house.
Security, Compliance, and Enterprise Features
For teams with serious requirements, Helicone offers:
- SOC-2 and HIPAA compliance (on Team and Enterprise plans)
- SAML SSO for enterprise authentication
- On-premises deployment options for companies that can’t send data externally
- Audit trails for all API activity
- Dedicated support with Slack integration (Team plan and above)
- Prompt management for version control and testing
The fact that Helicone is open-source also means you can audit the code yourself, which matters for security-conscious organizations. You’re not trusting a black box—you can see exactly what’s happening to your data.
Pricing: Fair, Transparent, and Actually Free to Start
Helicone’s pricing structure is one of its strongest selling points. Unlike some observability tools that charge per event or add markup to your API costs, Helicone is straightforward:
The Four Plans
Hobby: Free
- 10,000 requests/month
- Full dashboard
- Basic analytics
- Perfect for testing
Pro: $20/seat
- Everything in Hobby
- Scale beyond 10K
- Core observability
- ⭐ Most Popular
Team: $200/month
- Unlimited seats
- SOC-2/HIPAA
- Slack support
- ???? Best Value
Enterprise: Custom
- Custom MSA/SLAs
- SAML SSO
- On-premises
- Priority support
The Zero Markup Promise
This is critical: Helicone doesn’t mark up your LLM provider costs. You pay OpenAI (or Anthropic, or whoever) their standard rates, and you pay Helicone their flat platform fee. That’s it.
Many API gateway services add 10-20% markup on top of provider costs. Helicone doesn’t. This makes the economics work even at scale—you’re paying for the observability and tooling, not for routing your requests through their infrastructure.
For a startup using $5,000/month in OpenAI credits, that’s potentially $500-$1,000 saved compared to competitors who add markup.
Real-World Impact: The Numbers Tell the Story
Helicone isn’t a new experiment—it’s battle-tested infrastructure powering real products at scale. The stats from their homepage are impressive:
- 4.3 billion requests processed
- 8 trillion tokens logged
- 18.3 million users tracked
These aren’t vanity metrics—they represent actual production traffic from companies betting their AI features on Helicone’s reliability.
Notable Users and Use Cases
Companies using Helicone include Together.ai, Clay, Slant, and Flowine, among others. While detailed case studies aren’t publicly available, the use cases are clear:
- Startups optimizing costs: Switching between Claude and GPT-4 based on task complexity, using Helicone’s analytics to identify where cheaper models work fine.
- Enterprise teams ensuring compliance: Using Team plans for SOC-2/HIPAA requirements while maintaining observability across multiple AI features.
- Developers debugging production issues: Tracing hallucinations, token overruns, and unexpected errors back to specific prompts and user interactions.
- Product teams A/B testing models: Running experiments to see which LLM performs best for specific use cases, with full metrics for comparison.
The Open-Source Advantage
Helicone’s open-source nature creates a virtuous cycle. The community contributes improvements, new provider integrations, and bug fixes. You can join their Discord to get help, request features, or contribute code. The GitHub repository (4.7K stars) is active and well-maintained.
This matters because you’re not at the mercy of a closed-source vendor’s roadmap. If you need a feature, you can build it. If there’s a bug, you can fix it. And if Helicone ever shut down (unlikely but possible), you could self-host the entire stack.
How Helicone Stacks Up Against Alternatives
Let me be honest: Helicone isn’t the only option for LLM observability. Here’s how it compares to the alternatives I’ve tested:
Direct Provider Dashboards (OpenAI Platform, Anthropic Console)
✅ Free, native integration
❌ Only shows one provider’s data
❌ Limited analytics and debugging tools
❌ Can’t switch providers easily
LangFuse
✅ Open-source, good tracing
✅ Works well with LangChain
❌ More complex setup
❌ Doesn’t handle routing or failover
PromptLayer
✅ Similar observability features
❌ Closed-source
❌ Higher pricing at scale
❌ Less mature routing capabilities
OpenPipe
✅ Strong for fine-tuning workflows
❌ More specialized, less general-purpose
❌ Steeper learning curve
Building In-House
✅ Complete control
❌ Months of development time
❌ Ongoing maintenance burden
❌ Won’t match Helicone’s feature set without significant investment
Helicone’s Competitive Edge
What makes Helicone stand out:
- Ease of integration: Genuinely one-line change to existing code
- Zero markup pricing: Transparent costs that scale predictably
- Open-source trust: Audit the code, contribute features, self-host if needed
- Provider breadth: 100+ models means you’re not locked in
- Production reliability: Proven at scale with billions of requests
For most teams building AI products, Helicone hits the sweet spot of powerful features without overwhelming complexity.
Limitations and Areas for Improvement
No tool is perfect, and Helicone has some limitations worth noting:
Current Gaps
Not Every Provider is Fully Featured: While Helicone supports 100+ models, some newer or niche providers may not have complete feature parity. The team is actively adding support, but if you’re using a cutting-edge model, check compatibility first.
Premium Features Require Paid Plans: Advanced routing, prompt management, and compliance features are gated behind Team ($200/month) or Enterprise tiers. For hobbyists, this is fine. For startups, it can be a jump from the $20 Pro plan.
LLM-Specific Observability: Helicone is built for LLM APIs, not general-purpose backend monitoring. If you need observability for other services, you’ll need additional tools.
Learning Curve for Advanced Features: While basic integration is simple, setting up sophisticated routing rules or custom analytics requires digging into documentation. It’s not complex, but it’s not instant either.
High-Volume Pricing: Beyond the free tier, usage-based pricing kicks in. For apps with millions of requests, costs can add up (though still less than competitors with markup).
What’s on the Roadmap
Helicone is actively developed, with regular updates adding new models, features, and improvements. The open-source community contributes regularly, and the team is responsive to feature requests on Discord and GitHub.
Areas I’d like to see improved:
- More granular prompt versioning and A/B testing workflows
- Enhanced cost prediction and budget alerts
- Deeper integrations with workflow tools like LangChain and LlamaIndex
- More pre-built dashboard templates for common use cases
My Final Verdict: Who Should Use Helicone?
After extensive testing and comparison, here’s my assessment:
Helicone is a must-try tool for anyone building LLM-powered applications in 2025.
It solves real problems—provider flexibility, observability, cost management—in a way that’s both powerful and accessible. The free tier is generous enough for experimentation, and the paid plans scale reasonably for professional use.
Who Benefits Most from Helicone?
- Developers building AI apps: If you’re integrating LLMs into products, Helicone saves you from building custom logging and analytics.
- Startups hedging against vendor risk: The ability to switch providers protects you from price increases, API changes, or outages.
- Teams optimizing AI costs: The analytics help you identify where you’re overspending and where cheaper models can substitute.
- Enterprise/regulated industries: SOC-2, HIPAA compliance, and audit trails make Helicone viable for healthcare, finance, and government use cases.
- Open-source enthusiasts: The transparent, community-driven development aligns with open-source values while delivering production-grade infrastructure.
Who Might Look Elsewhere?
- Teams deeply committed to a single provider: If you’re only ever using OpenAI and never switching, the native dashboard might suffice (though you’d miss out on advanced analytics).
- Extremely cost-sensitive hobbyists: Beyond 10,000 requests/month, you’ll pay usage fees. For personal projects that stay tiny, this is still fine, but be aware.
- Organizations with hard data residency requirements: If you absolutely cannot route API traffic through third parties, you’d need Enterprise on-premises deployment.
The Bottom Line
Helicone is one of those rare developer tools that just works. It solves a real pain point (managing multiple LLM providers) with minimal friction (one-line integration), provides genuinely useful features (observability, routing, analytics), and does so at fair pricing (zero markup, generous free tier).
I’ve been reviewing tech for 15 years, and I can confidently say: if you’re building anything serious with LLMs, try Helicone. Start with the free plan, integrate it in five minutes, and see if the visibility alone doesn’t change how you develop and debug your AI features.
My recommendation: Try the free plan today. You’ve got nothing to lose and a much better development experience to gain.
FAQ: Quick Answers About Helicone
How fast is onboarding? Do I need to migrate my entire stack?
Onboarding takes less than 10 minutes. You don’t migrate anything—you just change your API base URL and add a header. Your existing code continues working unchanged.
Can I use Helicone with my own cloud-hosted models?
Yes! Helicone supports custom endpoints. If you’re running models on AWS, Azure, or your own infrastructure, you can still route through Helicone for observability.
Is support responsive, especially on lower-tier plans?
The community Discord is active and helpful for Free/Pro plans. Team plans get dedicated Slack support. From what I’ve seen, response times are reasonable—better than many larger platforms.
Does Helicone cache responses or modify my API calls?
By default, Helicone is a passthrough—it logs and routes but doesn’t cache or modify. You can enable optional caching features if desired, but it’s opt-in.
What happens if Helicone goes down? Does my app break?
Good question. If Helicone’s gateway is unreachable, your API calls would fail unless you have fallback logic. For mission-critical apps, consider implementing timeout and retry logic that can bypass Helicone in emergencies.
Further Resources and Next Steps
Ready to try Helicone? Here’s where to go:
- Official Website: helicone.ai
- Documentation: Comprehensive guides for every integration
- GitHub Repository: View source, contribute, report issues
- Discord Community: Get help, share feedback, connect with other developers
- Pricing Calculator: Estimate costs for your usage volume
Want to see it in action? Sign up for the free plan and integrate it into a test project. Within minutes, you’ll be seeing your LLM requests in a real-time dashboard—and you’ll wonder how you ever developed AI apps without this visibility.
Building something with AI? I track the best tools and strategies in this space. Follow my work for more in-depth, practical reviews that help you make smarter technology decisions.

About Alex Carter
AI tools expert with over 10 years of experience testing and reviewing technology products.