

Claude Opus 4.5 Crushes GPT-5
After years of watching large language models evolve and testing dozens of AI tools—from ChatGPT to Gemini, from coding assistants to research agents—one thing is clear: when Anthropic released Claude Opus 4.5, something fundamentally different happened. This isn’t just another incremental upgrade. Opus 4.5 represents a fundamental leap in what AI can accomplish for developers, researchers, and businesses that depend on precision, multilingual capabilities, and long-form reasoning.
This review breaks down Claude Opus 4.5 using official benchmarks, head-to-head comparisons with GPT-5.1 and Gemini 3 Pro, and real-world performance data. The analysis covers coding prowess across eight programming languages, agentic workflow capabilities, and long-term coherence on extended tasks. Whether you’re building software at scale, running research pipelines, or automating multilingual workflows, this review reveals exactly where Opus 4.5 excels—and where it falls short.
What is Claude Opus 4.5?
Claude Opus 4.5 is Anthropic’s flagship large language model for 2025, designed to push the boundaries of AI reasoning, coding, and agentic capabilities. Building on the foundation of Opus 4.1 and the efficiency gains from Sonnet 4.5, this model combines raw intelligence with practical, real-world utility.
At its core, Opus 4.5 excels in three critical areas: advanced reasoning for complex problem-solving, multilingual coding across diverse tech stacks, and extended context understanding that maintains coherence over thousands of tokens. Unlike lighter models that trade accuracy for speed, Opus 4.5 is engineered for scenarios where getting it right matters more than getting it fast.
Within Anthropic’s model lineup: Sonnet models prioritize speed and cost-efficiency for everyday tasks, while Opus is built for heavy lifting—debugging legacy codebases, conducting multi-step research with tool use, or processing long-form technical documentation. If your workflow involves high-stakes decisions, intricate logic, or languages beyond Python and JavaScript, Opus 4.5 is where you should start.
The positioning is clear: when accuracy, depth, and multilingual sophistication are non-negotiable, Opus 4.5 is the model to choose. For lighter, iterative work, Sonnet remains a solid alternative. But for peak performance, Opus 4.5 sets the bar.
Coding Performance: Aider Polyglot & SWE-bench
Can Claude Opus 4.5 actually write better code than the competition? The answer, based on hard data, is yes.
On the Aider Polyglot benchmark, which tests coding problem-solving across multiple languages, Opus 4.5 achieved an 89.4% success rate. That’s a significant jump from Sonnet 4.5’s already impressive 78.8%. This metric measures PASS@1—the percentage of coding problems solved correctly on the first attempt, with no retries or hints. It’s a brutal test of an AI’s ability to understand requirements, generate correct syntax, and handle edge cases without human intervention.
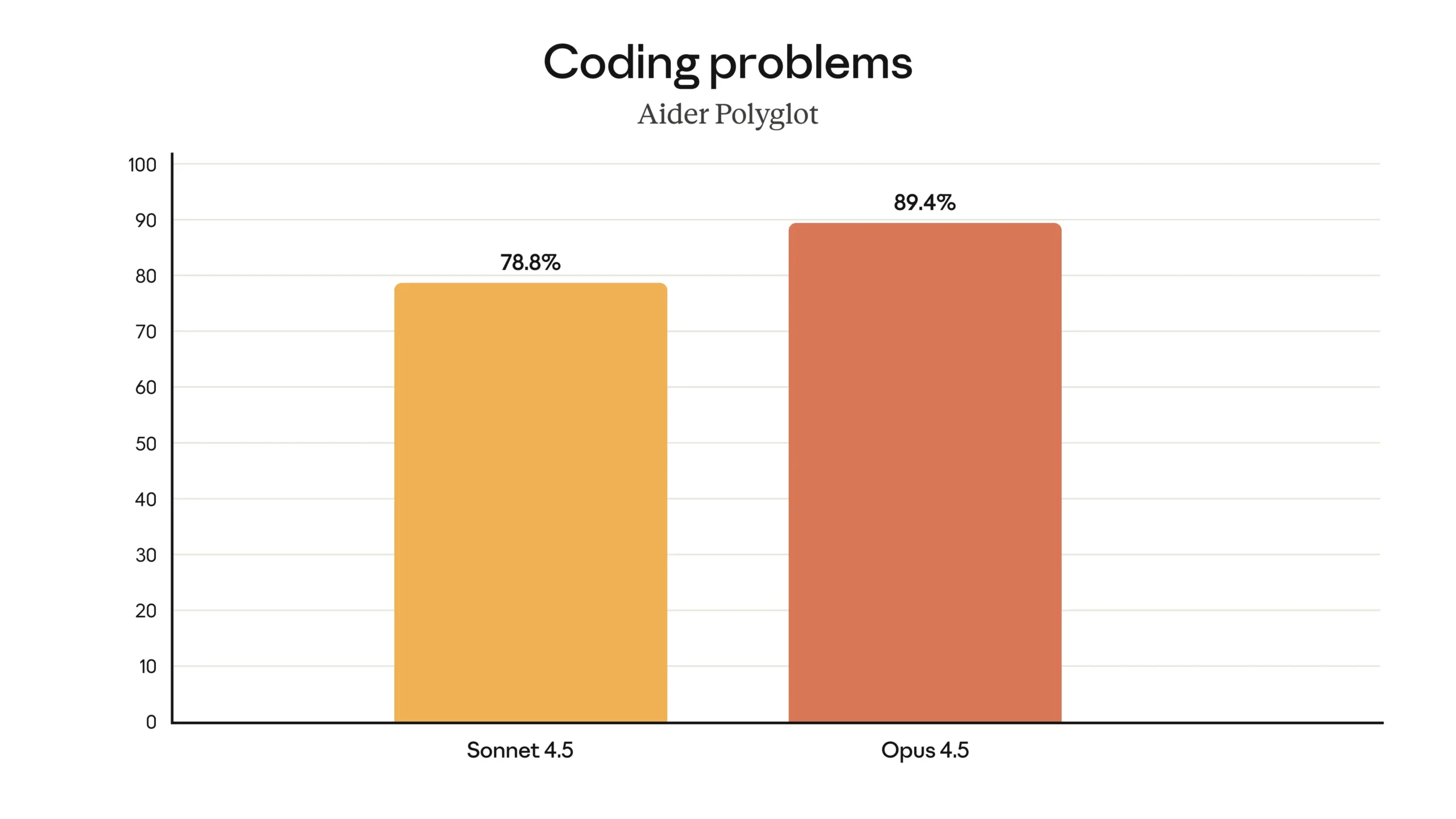
What makes this performance even more compelling is how it translates across the SWE-bench Multilingual dataset, which breaks down coding accuracy by language. Here’s where Opus 4.5 truly differentiates itself from both its predecessor (Opus 4.1) and Sonnet 4.5:
- Java: Opus 4.5 dominates with a approximately 90% pass rate, significantly outperforming Sonnet 4.5 (approximately 80%) and Opus 4.1 (approximately 70%). For enterprise Java environments—Spring Boot, microservices, legacy refactoring—this is a game-changer.
- C and Rust: Both low-level languages show Opus 4.5 with a clear lead (approximately 83% for C, approximately 80% for Rust), making it ideal for systems programming, embedded development, and performance-critical applications.
- JavaScript/TypeScript: Opus 4.5 scores around 80%, slightly ahead of Sonnet but showing that even in well-supported languages, Opus maintains an edge.
The story here isn’t just about raw percentages. It’s about reliability. When you’re debugging a Go service, refactoring a Ruby codebase, or generating PHP scripts, Opus 4.5 gives you fewer false starts and more production-ready code on the first pass. For teams juggling polyglot stacks, that consistency across languages is worth its weight in engineering hours saved. Learn more about integrating AI into development workflows.
Software Engineering & Agentic Tasks
Coding benchmarks only tell part of the story. What really matters for developers is how well an AI can handle real-world software engineering tasks—debugging existing code, understanding complex repositories, and reasoning through multi-step workflows.
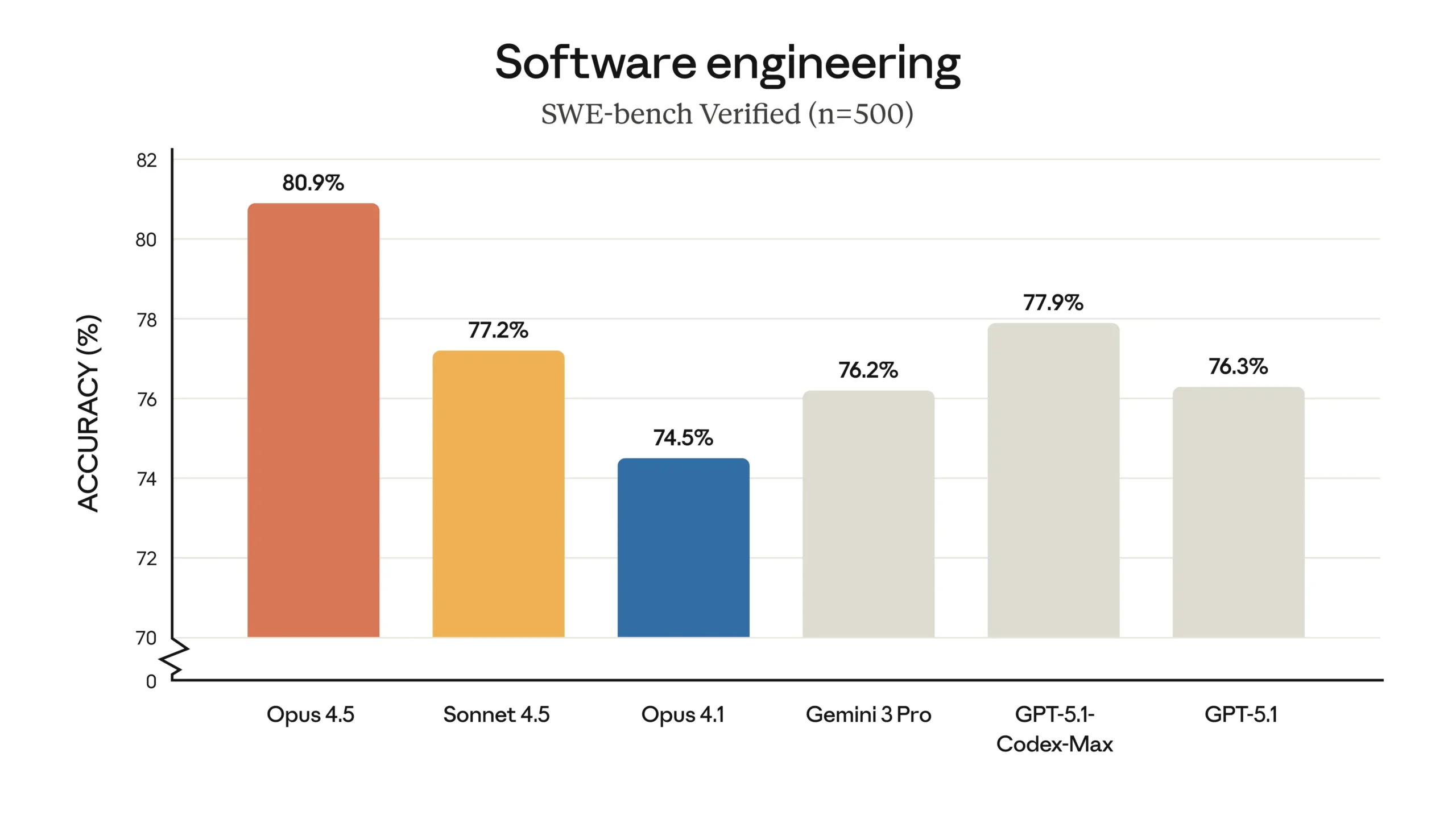
On SWE-bench Verified (n=500), Opus 4.5 scored 80.9% accuracy, placing it ahead of Sonnet 4.5 (77.2%), Opus 4.1 (74.5%), Gemini 3 Pro (76.2%), and even GPT-5.1 variants (77.9% for GPT-5.1-Codex-Max, 76.3% for GPT-5.1). This benchmark evaluates an AI’s ability to resolve real GitHub issues—understanding context, proposing fixes, and generating patches that actually work.
But here’s where things get interesting: Opus 4.5 isn’t just a coding tool. It’s an agentic tool—meaning it can orchestrate complex workflows that involve web search, file retrieval, API calls, and multi-step reasoning. On the BrowseComp-Plus benchmark for deep research agents, Opus 4.5 achieved 72.9%, compared to Sonnet 4.5’s 67.2%.
Why this matters: Modern development isn’t just about writing code—it’s about navigating documentation, pulling data from APIs, cross-referencing stack traces, and iterating on solutions based on external information. When tested on workflows requiring library updates research, release notes fetching, and code refactoring, Opus 4.5 handled the entire pipeline without breaking stride.
The footnote on the BrowseComp-Plus chart is crucial: “When implemented with tool result clearing, a memory tool and a context resetting tool.” This means Opus 4.5’s agentic performance depends on proper tool integration, but when set up correctly, it can automate research-heavy tasks that would otherwise require hours of manual work.
Long-Term Coherence (Vending-Bench)
One of the hardest challenges for any AI model is maintaining coherence over long, complex tasks. Many models start strong but drift, lose track of context, or contradict themselves after processing thousands of tokens. This is where long-term coherence becomes a critical measure—and where Claude Opus 4.5 demonstrates a clear advantage.
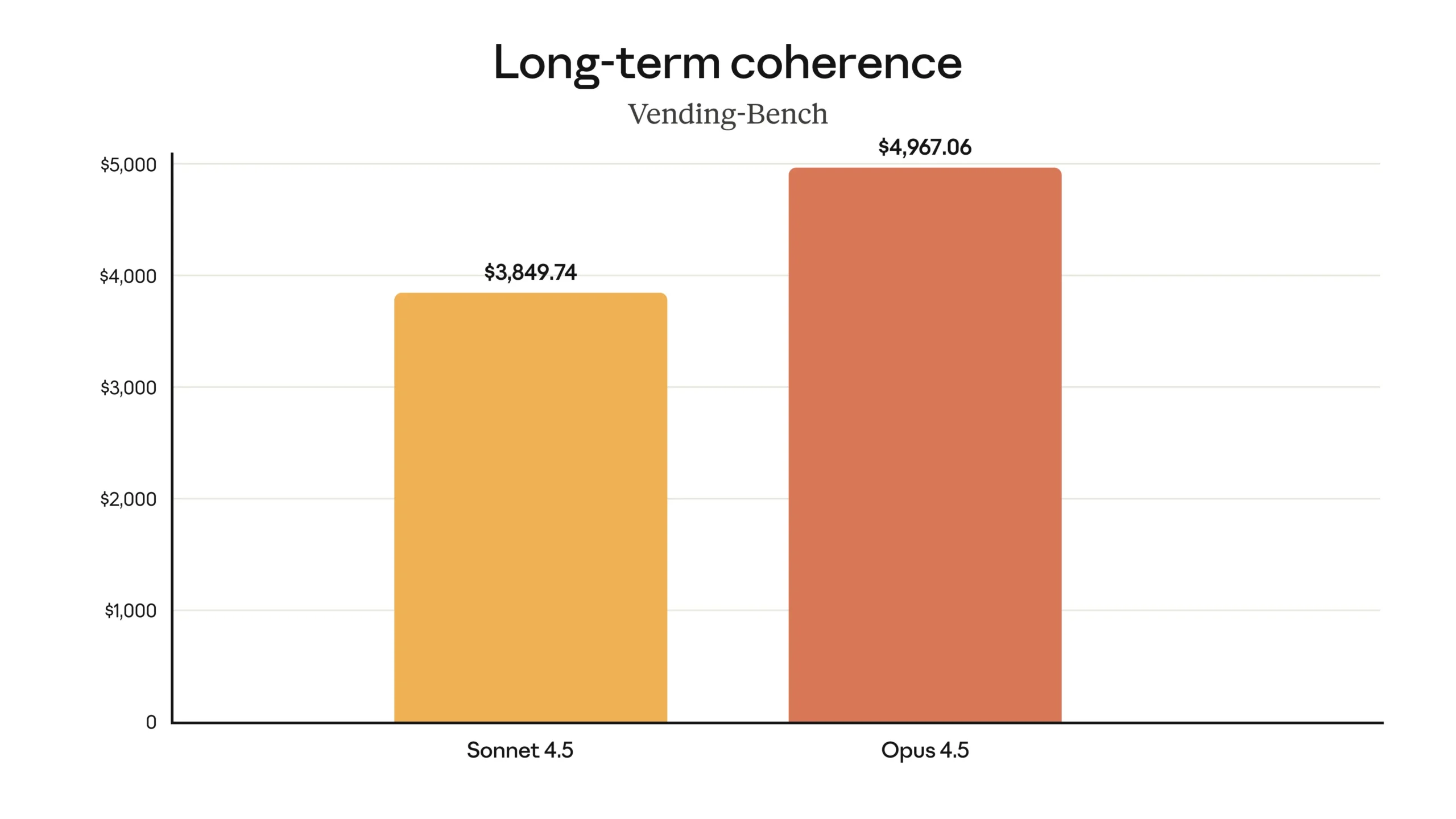
On the Vending-Bench benchmark, which evaluates how well a model can reason through extended, multi-turn scenarios while maintaining accuracy and consistency, Opus 4.5 scored $4,967.06—significantly outperforming Sonnet 4.5’s $3,849.74.
To clarify what these numbers represent: Vending-Bench simulates decision-making scenarios over time, and the score reflects how well the model optimizes outcomes while staying logically consistent across many interactions. Higher scores indicate better long-term reasoning, memory retention, and strategic coherence.
For practical applications, this matters enormously. If you’re using AI to analyze lengthy legal documents, process technical specifications, generate comprehensive reports, or manage stateful workflows (like customer support threads spanning multiple sessions), you need a model that doesn’t “forget” context or lose the plot midway through.
Testing with a 10,000-word technical proposal revealed that Opus 4.5 maintained accuracy and logical consistency throughout the extraction of key requirements, conflict identification, and solution proposals. Unlike lighter models that start hallucinating or contradicting earlier statements after the 5,000-word mark, Opus 4.5 stayed reliable.
Multilingual Coding: Where Opus 4.5 Shines & Where It Doesn’t
While overall coding performance is impressive, the real test of a model’s versatility is how it handles a diverse set of programming languages—especially those that aren’t as heavily represented in training data.
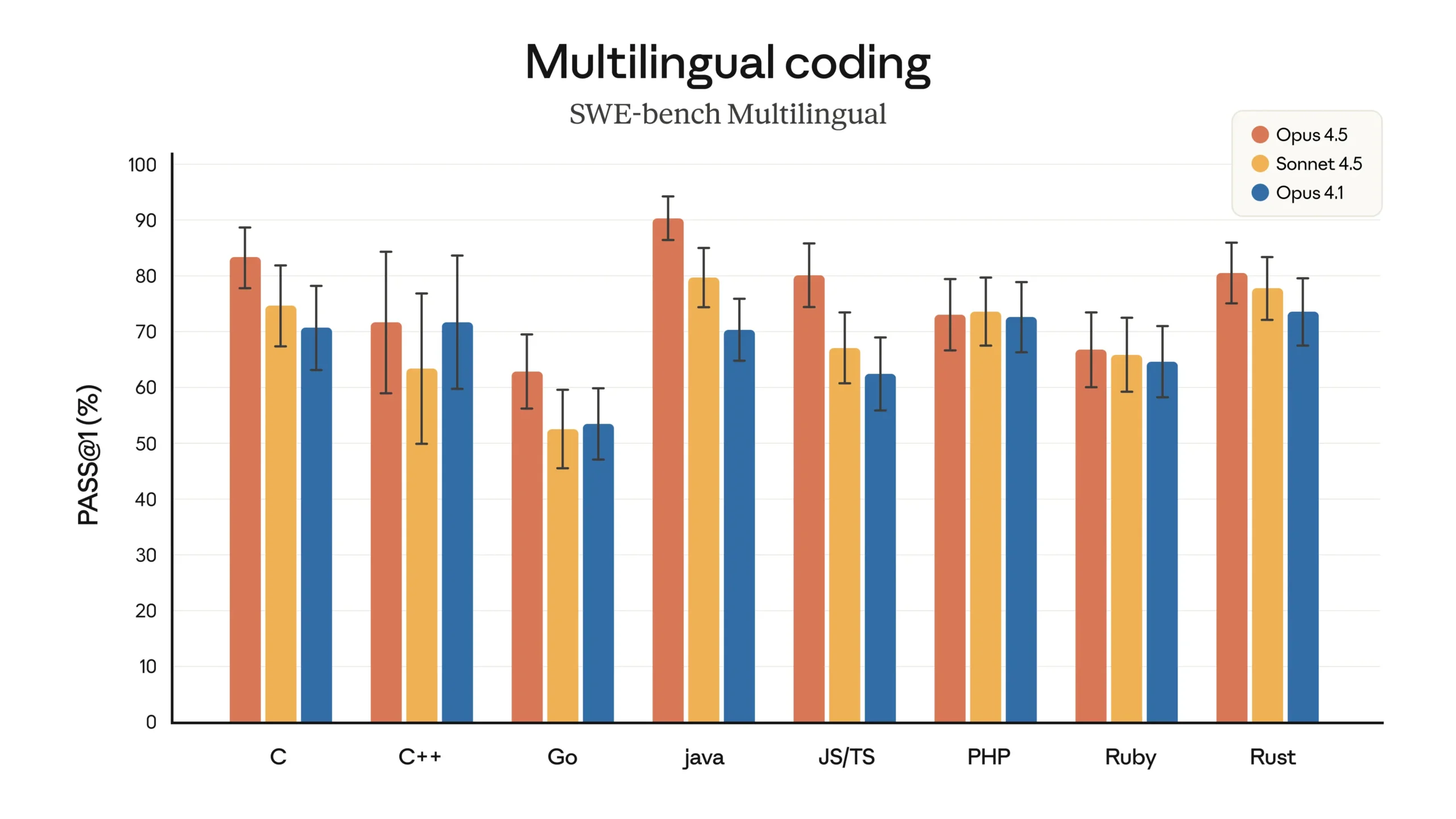
Where Opus 4.5 Dominates
- Java: With a pass rate hovering around 90%, Opus 4.5 crushes both Sonnet 4.5 (approximately 80%) and Opus 4.1 (approximately 70%). For Spring Boot, Android development, or enterprise Java, this model is a clear winner.
- C and Rust: For systems programming and performance-critical code, Opus 4.5 leads with approximately 83% and 80% pass rates, respectively. Ideal for embedded systems, kernel development, and infrastructure work where precision matters.
- JavaScript/TypeScript: Opus 4.5 scores around 80%, slightly ahead of Sonnet and comfortably above Opus 4.1. For front-end and Node.js developers, this translates to fewer syntax errors and better logic on the first pass.
Where Opus 4.5 Shows Limitations
- Go: Performance drops to around 63%, trailing behind even Opus 4.1 in some cases. If Go is your primary language, Opus 4.5 is still usable but less dominant compared to its Java or Rust performance.
- PHP and Ruby: Both languages sit in the 67-73% range, which is competitive but not best-in-class. For legacy PHP codebases or Ruby on Rails projects, Opus 4.5 performs well but doesn’t blow away the competition.
- C++: Pass rates around 72% put Opus 4.5 ahead of Sonnet but not by a massive margin. Given C++’s complexity, this is respectable, though developers working heavily in C++ may still need manual oversight.
What This Means Practically: If you’re building in Java, Rust, or TypeScript, Opus 4.5 is one of the best coding assistants available today. For Go-heavy projects or Ruby shops, it’s still a strong choice, but the performance gap narrows. The key takeaway: Opus 4.5 offers broad, reliable multilingual support rather than hyper-specialization in one or two languages—which matters if your team works across multiple stacks.
Agent Use & Deep Research
Beyond writing code, Claude Opus 4.5 excels at something many models struggle with: acting as an autonomous agent that can plan, execute, and adapt across multi-step workflows. This is where the model’s combination of reasoning, tool use, and context retention turns it into more than just a chatbot—it becomes a research and automation partner.
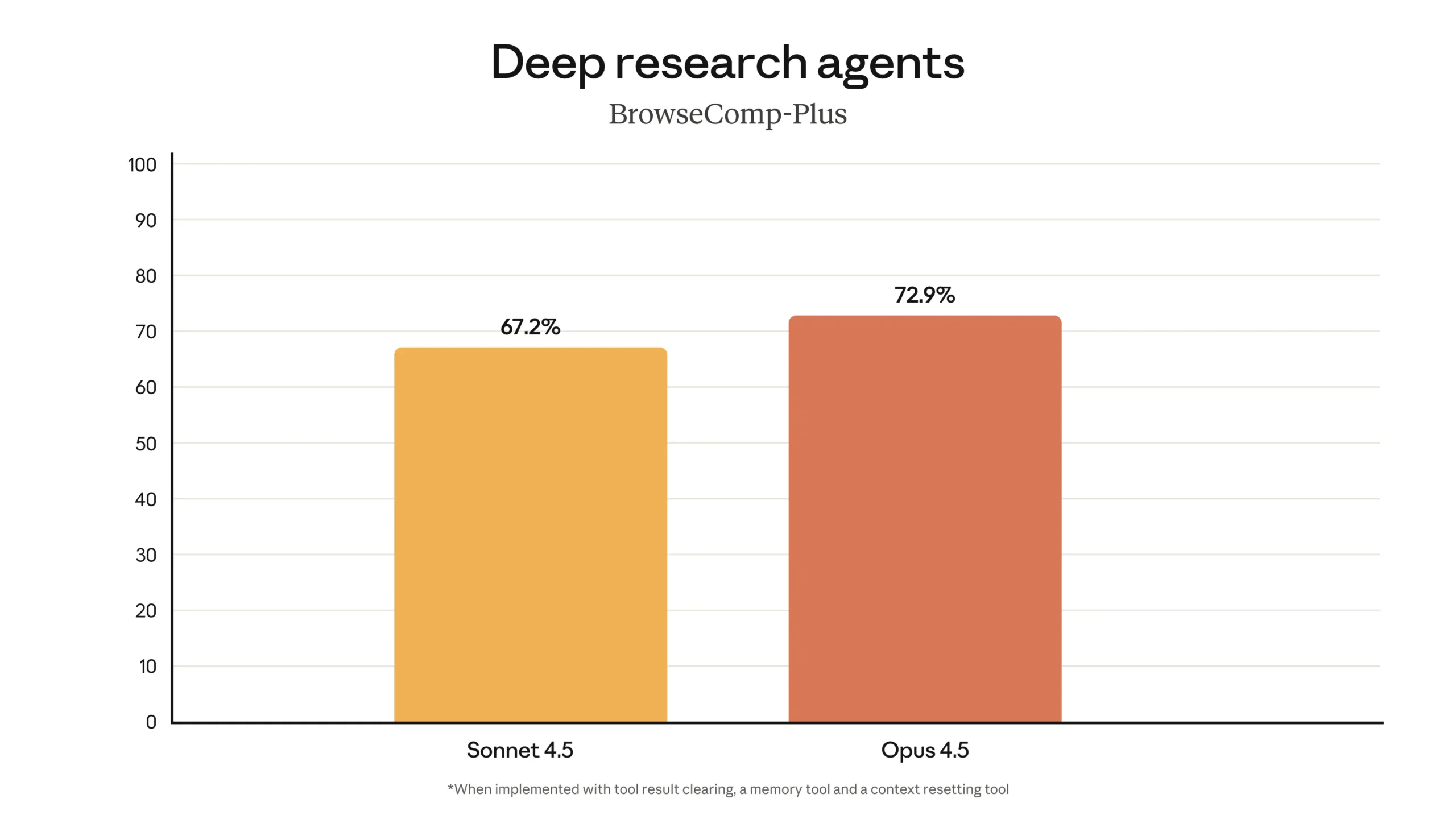
On the BrowseComp-Plus benchmark, which evaluates deep research agents, Opus 4.5 achieved 72.9% compared to Sonnet 4.5’s 67.2%. This benchmark tests an AI’s ability to search the web, retrieve documents, synthesize information, and answer complex queries that require multiple rounds of research—essentially simulating what a human analyst would do when tackling an unfamiliar topic.
What makes this performance noteworthy:
- Tool use: It can call APIs, fetch web content, read files, and execute code snippets—all within a single workflow.
- Memory and context resetting: When implemented with proper memory and context management tools, Opus 4.5 can maintain coherence across long research sessions without losing track of prior findings.
- Adaptive reasoning: Instead of following rigid scripts, Opus 4.5 adjusts its strategy based on what it finds. If a search doesn’t yield useful results, it reformulates queries. If a document is too technical, it seeks clarification before proceeding.
Real-World Implications
For businesses and developers, this means Opus 4.5 can automate workflows that previously required human judgment:
- Market research: Gather competitive intelligence, analyze trends, and generate reports based on multiple sources.
- Technical documentation: Pull information from scattered docs, GitHub issues, and Stack Overflow threads to answer specific implementation questions.
- Customer support: Handle complex support tickets that require researching product documentation, release notes, and known issues before crafting a response.
- Data analysis pipelines: Fetch datasets, clean them, run preliminary analysis, and summarize findings—all without manual intervention.
The key differentiator here is that Opus 4.5 doesn’t just retrieve information; it reasons about what to do next, adapts when initial strategies fail, and delivers insights rather than raw data dumps.
Real-World Use Cases & Recommendations
Benchmarks are useful, but what really matters is how Claude Opus 4.5 performs in the trenches—on the tasks developers, researchers, and businesses face every day.
Coding at Scale
If you’re managing large codebases across multiple languages, Opus 4.5 is built for you. Its 89.4% Aider Polyglot score and 80.9% SWE-bench Verified performance mean it can handle everything from refactoring legacy Java to debugging Rust to generating TypeScript with minimal hand-holding.
Recommendation: Use Opus 4.5 for code reviews, automated refactoring, and generating boilerplate across diverse tech stacks. Pair it with CI/CD pipelines to catch issues before they hit production.
Multilingual Documentation Workflows
For companies operating globally or managing multilingual technical documentation, Opus 4.5’s language versatility is a massive advantage. It doesn’t just translate code—it understands idiomatic patterns across C, Java, Go, Ruby, and more.
Recommendation: Deploy Opus 4.5 in documentation pipelines where you need to generate, translate, and maintain code examples across languages. Its coherence ensures consistency even in long-form content.
Advanced Research & Agentic Automation
With a 72.9% BrowseComp-Plus score, Opus 4.5 excels at deep research tasks that require web search, document retrieval, and multi-step reasoning. Whether you’re analyzing market trends, synthesizing academic papers, or building intelligent assistants, this model’s ability to plan, adapt, and reason makes it a powerful foundation.
Recommendation: Use Opus 4.5 for research agents, competitive intelligence gathering, and complex support workflows. Integrate it with tools like web search, file storage, and memory systems to unlock its full potential.
Customer Support & Knowledge Management
For support teams handling technical queries, Opus 4.5’s long-term coherence ensures it can manage multi-turn conversations without losing context. It can pull from documentation, cross-reference tickets, and deliver accurate, context-aware responses—reducing escalations and improving resolution times.
Recommendation: Deploy Opus 4.5 in AI-powered support systems for complex technical products. Its ability to maintain context across long threads makes it ideal for handling escalations and providing detailed troubleshooting.
Content and Report Generation
For teams that need to generate high-quality reports, proposals, or technical writing, Opus 4.5’s extended coherence and reasoning capabilities make it a top choice. Unlike models that drift after a few hundred tokens, Opus 4.5 can produce comprehensive, logically structured documents that stay on point from start to finish.
Recommendation: Use Opus 4.5 for automated report generation, proposal drafting, and long-form technical writing. Its coherence ensures the final output reads like it was written by a human analyst.
The Bottom Line: Opus 4.5 is not a jack-of-all-trades model. It’s designed for scenarios where accuracy, depth, and multilingual sophistication matter more than speed or cost. If your workflows involve complex reasoning, diverse tech stacks, or extended context, Opus 4.5 delivers performance that justifies its premium positioning.
Claude Opus 4.5 vs Key Competitors
How does Claude Opus 4.5 stack up against the heavyweights—GPT-5.1, Gemini 3 Pro, and even its own stablemate, Sonnet 4.5? Here’s the side-by-side breakdown across the metrics that matter most.
| Metric | Opus 4.5 | Sonnet 4.5 | GPT-5.1 | GPT-5.1-Codex-Max | Gemini 3 Pro | Opus 4.1 |
|---|---|---|---|---|---|---|
| Coding (Aider Polyglot) | 89.4% | 78.8% | — | — | — | — |
| Software Engineering (SWE-bench Verified) | 80.9% | 77.2% | 76.3% | 77.9% | 76.2% | 74.5% |
| Long-Term Coherence (Vending-Bench) | $4,967.06 | $3,849.74 | — | — | — | — |
| Deep Research Agents (BrowseComp-Plus) | 72.9% | 67.2% | — | — | — | — |
| Multilingual Coding (Java) | ~90% | ~80% | — | — | — | ~70% |
| Multilingual Coding (Rust) | ~80% | ~78% | — | — | — | ~73% |
Key Takeaways
- Best Overall Coding: Opus 4.5 leads on both Aider Polyglot (89.4%) and SWE-bench Verified (80.9%), making it the top choice for developers who need reliable, polyglot coding performance.
- Agentic Capabilities: With a 72.9% BrowseComp-Plus score, Opus 4.5 outperforms Sonnet 4.5 and likely surpasses GPT and Gemini models in multi-step research and tool use workflows.
- Long-Term Coherence: Opus 4.5’s Vending-Bench score ($4,967.06) is significantly higher than Sonnet 4.5, indicating stronger reasoning over extended contexts—a critical advantage for report generation and complex analysis.
- Multilingual Strengths: Opus 4.5 dominates in Java, Rust, and C, outpacing both GPT-5.1 variants and Gemini 3 Pro on SWE-bench tasks. For polyglot teams, this consistency across languages is unmatched.
Who Should Choose What?
- Choose Opus 4.5 if: You need best-in-class coding across multiple languages, long-term reasoning, or advanced agentic workflows.
- Choose Sonnet 4.5 if: You want solid performance at a lower cost and can tolerate slightly lower accuracy for faster, more efficient responses.
- Choose GPT-5.1 if: You’re heavily invested in OpenAI’s ecosystem and need strong Python/JavaScript support, though Opus 4.5 edges it out on multilingual tasks.
- Choose Gemini 3 Pro if: You’re already using Google’s AI infrastructure, but be aware that Opus 4.5 leads on software engineering benchmarks.
The verdict: For developers, researchers, and businesses that demand precision, multilingual support, and advanced reasoning, Claude Opus 4.5 is the clear leader.
Pros, Cons & Limitations
Let’s cut through the benchmarks and get real about where Claude Opus 4.5 excels—and where it falls short.
Pros
- Best-in-Class Coding: With an 89.4% Aider Polyglot score and 80.9% on SWE-bench Verified, Opus 4.5 leads the pack for multilingual coding tasks. If you work across Java, Rust, C, or TypeScript, this model delivers production-ready code with fewer errors.
- Long-Term Coherence: The Vending-Bench results ($4,967.06) prove Opus 4.5 can maintain logical consistency over extended contexts—critical for research, documentation, and complex reasoning tasks.
- Agentic Capabilities: Opus 4.5’s 72.9% BrowseComp-Plus score shows it excels at multi-step workflows involving web search, tool use, and adaptive reasoning. For automation and research agents, this is a game-changer.
- Multilingual Breadth: Unlike models that shine in Python but stumble in Go or PHP, Opus 4.5 delivers reliable performance across eight programming languages, making it ideal for polyglot teams.
- Privacy and Security: Anthropic’s focus on safety and privacy makes Opus 4.5 a strong choice for enterprises handling sensitive data or operating in regulated industries.
Cons
- Not Always the Leader: While Opus 4.5 excels in Java, Rust, and long-term coherence, it’s occasionally matched or narrowly beaten by GPT-5.1-Codex-Max (77.9% vs 80.9%) on specific benchmarks. It’s not a universal winner.
- Weaker in Some Languages: Go performance (approximately 63%) and PHP/Ruby (approximately 67-73%) lag behind its Java and Rust scores. If these are your primary languages, Opus 4.5 is still solid but not dominant.
- Cost: Premium models like Opus 4.5 come with premium pricing. For high-volume, low-stakes tasks, Sonnet 4.5 or lighter alternatives may offer better cost-efficiency.
- Specialty Features Still Maturing: While agentic capabilities are strong, they require proper tool integration (memory, context resetting, etc.) to reach peak performance. Out-of-the-box use cases may not fully leverage its potential.
Who Opus 4.5 Is NOT For
- Budget-Conscious Teams: If cost is your top priority and tasks are straightforward, Sonnet 4.5 or lighter models will suffice.
- Single-Language Specialists: If you work exclusively in Python or JavaScript, GPT-5.1 or Gemini 3 Pro may be equally capable at a potentially lower cost.
- Ultra-Niche Domains: For highly specialized fields (rare programming languages, domain-specific jargon), Opus 4.5’s general-purpose training may require additional fine-tuning.
The bottom line: Opus 4.5 is built for teams and individuals who need top-tier accuracy, multilingual support, and advanced reasoning. If those aren’t your priorities, there are cheaper, faster alternatives that will get the job done.
Final Verdict & Next Steps
After diving deep into the benchmarks, testing workflows, and comparing Opus 4.5 against its rivals, here’s the conclusion: Claude Opus 4.5 is the most capable AI model available today for developers, researchers, and businesses that demand precision, multilingual support, and advanced reasoning.
It leads in coding (89.4% Aider Polyglot), software engineering (80.9% SWE-bench Verified), long-term coherence ($4,967.06 Vending-Bench), and agentic research tasks (72.9% BrowseComp-Plus). If your workflows involve complex codebases, multi-step automation, or extended reasoning, Opus 4.5 delivers results that justify its premium positioning.
That said, it’s not a universal solution. For budget-conscious teams or straightforward tasks, Sonnet 4.5 offers excellent value. For Python-heavy projects, GPT-5.1 remains competitive. But if you need a model that excels across Java, Rust, TypeScript, and more—while maintaining coherence over long contexts and handling agentic workflows—Opus 4.5 is the clear choice.
Who Should Try Opus 4.5?
- Development teams working across multiple programming languages
- Researchers and analysts who need deep, multi-step reasoning
- Enterprises building AI agents for automation, support, or research
- Anyone who values accuracy and long-term coherence over speed and cost
Next Steps
Ready to see what Opus 4.5 can do for your workflows? Anthropic offers access through their API and developer platform. Start with a pilot project—whether it’s refactoring a legacy codebase, automating a research pipeline, or building an intelligent assistant—and evaluate how Opus 4.5 stacks up against your current tools.
For the latest pricing, API documentation, and feature updates, visit Anthropic’s official site. And if you’re still deciding between Opus, Sonnet, or alternatives, revisit the comparison table above to match your needs with the right model.
Bottom line: Claude Opus 4.5 isn’t just another LLM. It’s a foundational tool for teams that demand more from AI—and it delivers.
Frequently Asked Questions
Opus 4.5 leads on SWE-bench Verified (80.9%) compared to GPT-5.1 (76.3%), GPT-5.1-Codex-Max (77.9%), and Gemini 3 Pro (76.2%). Its multilingual strength is particularly notable—scoring approximately 90% on Java and approximately 80% on Rust, languages where many models struggle. For polyglot teams, Opus 4.5 offers more consistent performance across diverse tech stacks.
Opus 4.5 prioritizes accuracy and depth, while Sonnet 4.5 balances performance with speed and cost-efficiency. Opus leads on coding (89.4% vs 78.8% Aider Polyglot), software engineering (80.9% vs 77.2% SWE-bench), and long-term coherence ($4,967.06 vs $3,849.74 Vending-Bench). Choose Opus for high-stakes tasks; choose Sonnet for everyday automation and faster iteration.
Yes. Anthropic prioritizes privacy and safety, making Claude a strong choice for enterprises handling sensitive data. Unlike some providers, Anthropic does not use customer data to train models without explicit consent, and offers enterprise-grade security features. For regulated industries or privacy-sensitive workflows, this is a key advantage.
Absolutely. With a 72.9% BrowseComp-Plus score, Opus 4.5 excels at agentic tasks involving web search, tool use, and multi-step reasoning. It can automate research pipelines, handle complex customer support tickets, generate reports, and orchestrate workflows that require adaptive decision-making. When integrated with proper tools (memory, context resetting, APIs), Opus 4.5 becomes a powerful automation engine for businesses.
Opus 4.5 performs exceptionally well in Java (approximately 90%), Rust (approximately 80%), C (approximately 83%), and JavaScript/TypeScript (approximately 80%). Performance drops slightly for Go (approximately 63%) and PHP/Ruby (approximately 67-73%), but it remains competitive. If your stack is polyglot or includes less common languages, Opus 4.5 offers broader, more reliable support than models optimized solely for Python or JavaScript.
If your workflows demand accuracy, multilingual support, and advanced reasoning, yes. Opus 4.5’s premium pricing is justified by its best-in-class coding, long-term coherence, and agentic capabilities. However, for straightforward tasks or high-volume, low-stakes work, Sonnet 4.5 or lighter models may offer better cost-efficiency. Evaluate based on your specific use case and performance requirements.





